public int[] getReportCounts(HashMap<String, String> map, String[] list, int cnt) {
int[] result = new int[cnt];
for (String reporter : list) {
int index = Integer.parseInt(map.get((reporter).split(" ")[1]));
result[index] += 1;
}
return result;
}
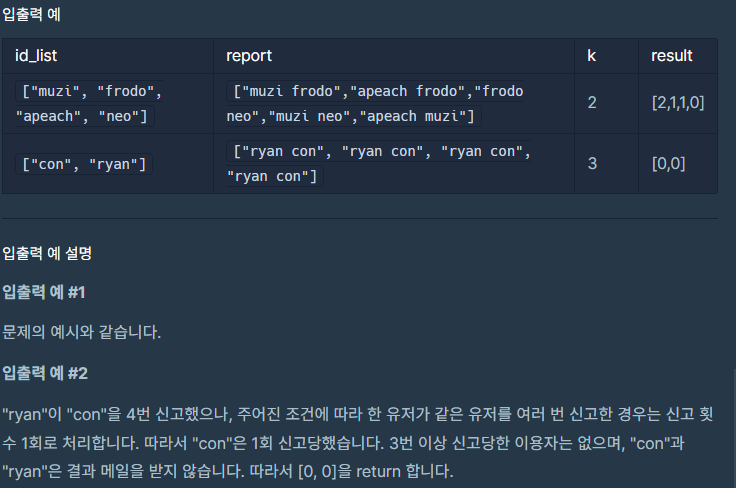
4. 받은 메일 결과 반환 신고 내역을 취합한 기준으로 정지 기준 횟수가 해당되는 경우 메일 발송 대상자로 체크합니다. 그리고 각 유저가 몇 번의 메일을 받았는지 최종 결과로 반환해줍니다. getMailCounts 함수로 기능을 구현했습니다.
public int[] getMailCounts(HashMap<String, String> map, String[] list, int[] reportCounts, int k) {
int[] result = new int[reportCounts.length];
for (String reporter : list) {
int index = Integer.parseInt(map.get((reporter).split(" ")[1]));
if (reportCounts[index] < k) continue;
int answerIndex = Integer.parseInt(map.get((reporter).split(" ")[0]));
result[answerIndex] += 1;
}
return result;
}
전체코드
public HashMap<String, String> setId(String[] id_list) {
HashMap<String, String> map = new HashMap<>();
for (int i = 0; i < id_list.length; i++) {
map.put(i+"", id_list[i]);
map.put(id_list[i], i+"");
}
return map;
}
public int[] getReportCounts(HashMap<String, String> map, String[] list, int cnt) {
int[] result = new int[cnt];
for (String reporter : list) {
int index = Integer.parseInt(map.get((reporter).split(" ")[1]));
result[index] += 1;
}
return result;
}
public int[] getMailCounts(HashMap<String, String> map, String[] list, int[] reportCounts, int k) {
int[] result = new int[reportCounts.length];
for (String reporter : list) {
int index = Integer.parseInt(map.get((reporter).split(" ")[1]));
if (reportCounts[index] < k) continue;
int answerIndex = Integer.parseInt(map.get((reporter).split(" ")[0]));
result[answerIndex] += 1;
}
return result;
}
public int[] solution(String[] id_list, String[] report, int k) {
// 1. 아이디 리스트 정렬
HashMap<String, String> map = setId(id_list);
// 2. 신고 내역 중복 제거
String[] list = Arrays.stream(report).distinct().toArray(String[]::new);
// 3. 신고 내역 취합
int[] reportCounts = getReportCounts(map, list, id_list.length);
// 4. 받은 메일 결과 반환
return getMailCounts(map, list, reportCounts, k);
}
후기
* 난이도 (5점 만점)
5 : 풀 줄 알면 기업 코딩 테스트는 문제없음.
4 : 평균적인 기업 코딩 테스트의 중간 이상.
3 : 평균적인 기업 코딩테스트의 쉬운 문제.
2 : 알고리즘 문제를 연습하고 있다면 풀 수 있는 문제.
1 : 시간이 오래 걸리지 않고, 누구나 풀 수 있는 문제.
[카카오 코딩 테스트 2022 신입 공채] 신고 결과 받기는 평균적인 기업 코딩테스트 문제로 보입니다. 난이도나 문제 유형이 코딩테스트를 볼 때 출제되는 문제와 흡사했습니다. 한 번 씩 풀어보시길 바랍니다.
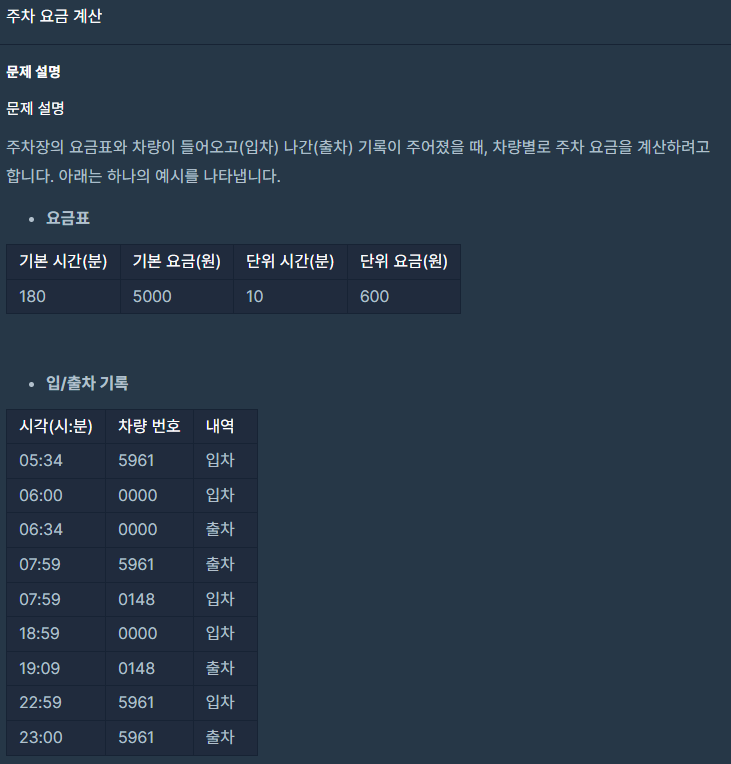
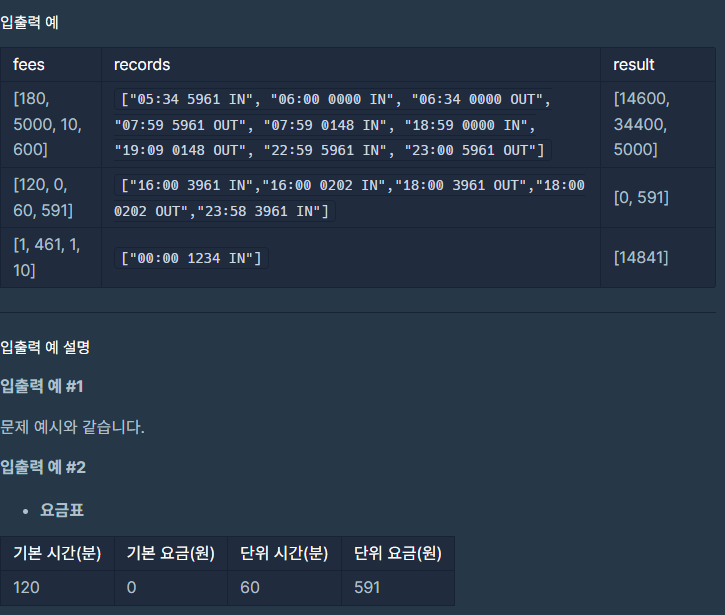
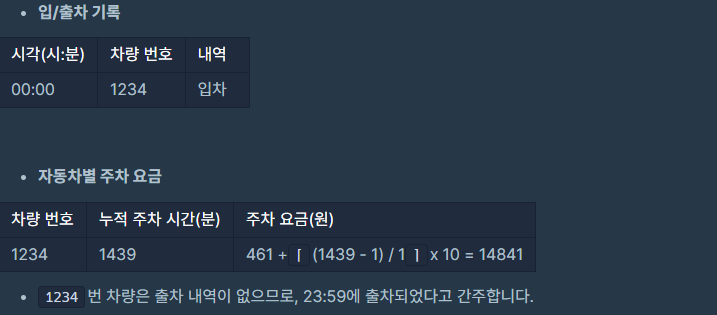
1. 누적 입/출차 시간 계산 2. 출차된 내역 없는 차량 시간 계산 3. 차량 번호 정렬 4. 요금 정산
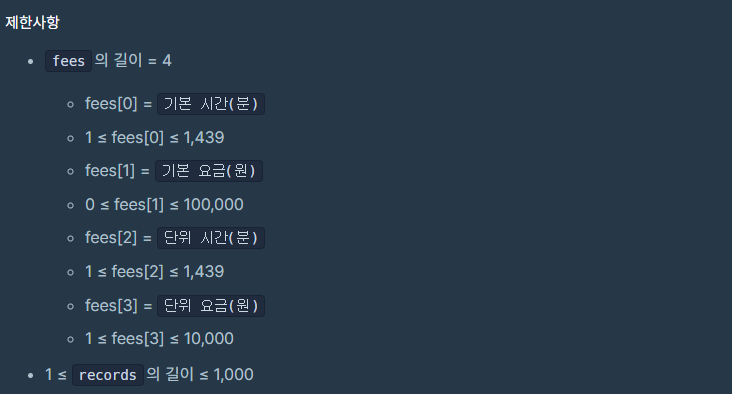
순서로 문제를 풀었습니다. Int[] fees: 각 원소는 "기본 시간(분), 기본 요금(원), 단위 시간(분), 단위 요금(원)" 형식의 숫자입니다. String[] records: 각 원소는 "시각, 차량번호, 내역" 형식의 문자열입니다.
1. 누적 입/출차 시간 계산 records 배열만큼 반복문을 이용했습니다. split 함수를 이용하여 records 각 원소의 "시각, 차량번호, 내역"을 구분하였습니다.
// 1.누적 입/출차 시간 계산
for (String record : records) {
String[] arr = record.split(" ");
}
parkingTime 이라는 함수를 만들어서 입/출차 시간을 계산했습니다. record 매개변수는 각 원소의 "시각, 차량번호, 내역"을 순서대로 갖고 있기 때문에 시각: time 차량번호: carNumber 내역: inOut 으로 분류했습니다.
내역이 IN 이면 Map에 해당 데이터를 저장하고 Out 이면 저장되어 있는 데이터를 꺼내서 IN 시간과 OUT 시간을 계산 후 누적 주차 시간을 구했습니다.
public void parkingTime(String[] record) {
String time = record[0];
String carNumber = record[1];
String inOut = record[2];
if ("IN".equals(inOut)) {
parkingMap.put(carNumber, time);
return;
}
int inTime = toMinutes(parkingMap.get(carNumber).split(":"));
int outTime = toMinutes(time.split(":"));
int useTime = outTime - inTime;
parkingMap.remove(carNumber);
if (resultMap.containsKey(carNumber)) {
resultMap.put(carNumber, resultMap.get(carNumber) + useTime);
return;
}
resultMap.put(carNumber, useTime);
}
// 1.누적 입/출차 시간 계산
for (String record : records) {
String[] arr = record.split(" ");
parkingTime(arr);
}
중복을 제외한 입차된 차량 수를 구하기 위해 Set을 이용하였습니다. Set에 차량번호가 이미 있다면 카운트를 올리지 않고, 차량번호가 없을 경우만 카운트를 올립니다.
// 1.누적 입/출차 시간 계산
Set<String> car = new HashSet<>();
int cnt = 0;
for (String record : records) {
String[] arr = record.split(" ");
parkingTime(arr);
if (car.contains(arr[1])) continue;
car.add(arr[1]);
cnt++;
}
2. 출차된 내역 없는 차량 시간 계산 records 배열에 있는 입/출차 시간을 계산 후 아직 출차되지 않은 차가 있다면 23:59로 계산하여 출차시킵니다. 출차되지 않은 차량 기준은 내역이 IN 이면 Map에 해당 데이터를 저장하고 OUT이 없어서 꺼내지 못한 데이터입니다. lastTime이라는 함수에 구현하였습니다. parkingMap은 IN 데이터를 저장해놓은 HashMap입니다.
// 2.출차된 내역 없는 차량 시간 계산
for (Map.Entry<String, String> map : parkingMap.entrySet()) {
lastTime(map.getKey(), map.getValue());
}
public void lastTime(String carNumber, String time) {
int inTime = toMinutes(time.split(":"));
int outTime = toMinutes("23:59".split(":"));
int useTime = outTime - inTime;
if (resultMap.containsKey(carNumber)) {
resultMap.put(carNumber, resultMap.get(carNumber) + useTime);
return;
}
resultMap.put(carNumber, useTime);
}
3. 차량 번호 정렬 입/출차 시간이 계산된 Map을 list로 변환하여 차량 번호 순서대로 정렬했습니다. 정렬하는 이유는 반환하는 차량 번호를 차량 번호 순서대로 해야 하기 때문입니다.
// 3.차량 번호 정렬
List<String> keyList = new ArrayList<>(resultMap.keySet());
Collections.sort(keyList);
4. 요금 정산 입/출차 시간이 계산된 데이터와 차량 번호 순서로 정렬되어 있으니 요금 정산 후 반환해주면 완료입니다. 반환할 배열을 생성합니다. 배열 수는 처음에 중복을 제외한 입차 된 차량 수를 담은 cnt라는 변수를 사용합니다.
int[] answer = new int[cnt];
반복문을 사용하여 차량 번호 순서로 요금 정산을 해줍니다. 요금 정산은 calculate라는 함수를 만들어서 계산했습니다.
// 4.요금 정산
int[] answer = new int[cnt];
int index = 0;
for (String key : keyList) {
answer[index] = calculate(fees, resultMap.get(key));
index++;
}
calculate의 매개변수는 fees(요금표)와 parkingTime(누적 주차 시간)을 받습니다. 만약 누적 주차 시간이 기본 이용 시간보다 적거나 같으면 기본 이용 요금을 지불합니다. 누적 주차 시간이 기본 이용 시간보다 많다면 기본 이용 시간을 제외 후 나머지 시간을 계산합니다. 단위 시간만큼 몫을 구하고 나머지 시간이 있다면 단위시간 1회 더 해당하는 것으로 간주합니다.
ex. 단위 시간: 10분 단위 요금: 100원 이용시간: 11분 지불금액: 200원
public int calculate(int[] fees, int parkingTime) {
int defaultTime = fees[0];
int defaultPay = fees[1];
int time = fees[2];
int pay = fees[3];
int useTime = parkingTime;
if (defaultTime >= useTime) {
return defaultPay;
}
useTime -= defaultTime;
int quotient = useTime / time;
if (quotient == 0) {
quotient = 1;
return defaultPay + (pay * quotient);
}
if (((quotient * time) - useTime) != 0) {
quotient += 1;
}
return defaultPay + (pay * quotient);
}
전체 코드
HashMap<String, String> parkingMap = new HashMap<>();
HashMap<String, Integer> resultMap = new HashMap<>();
public int[] solution(int[] fees, String[] records) {
// 1.누적 입/출차 시간 계산
Set<String> car = new HashSet<>();
int cnt = 0;
for (String record : records) {
String[] arr = record.split(" ");
parkingTime(arr);
if (car.contains(arr[1])) continue;
car.add(arr[1]);
cnt++;
}
// 2.출차된 내역 없는 차량 시간 계산
for (Map.Entry<String, String> map : parkingMap.entrySet()) {
lastTime(map.getKey(), map.getValue());
}
// 3.차량 번호 정렬
List<String> keyList = new ArrayList<>(resultMap.keySet());
Collections.sort(keyList);
// 4.요금 정산
int[] answer = new int[cnt];
int index = 0;
for (String key : keyList) {
answer[index] = calculate(fees, resultMap.get(key));
index++;
}
return answer;
}
public void parkingTime(String[] record) {
String time = record[0];
String carNumber = record[1];
String inOut = record[2];
if ("IN".equals(inOut)) {
parkingMap.put(carNumber, time);
return;
}
int inTime = toMinutes(parkingMap.get(carNumber).split(":"));
int outTime = toMinutes(time.split(":"));
int useTime = outTime - inTime;
parkingMap.remove(carNumber);
if (resultMap.containsKey(carNumber)) {
resultMap.put(carNumber, resultMap.get(carNumber) + useTime);
return;
}
resultMap.put(carNumber, useTime);
}
public int toMinutes(String[] time) {
int hour = Integer.parseInt(time[0]) * 60;
int minute = Integer.parseInt(time[1]);
return hour + minute;
}
public void lastTime(String carNumber, String time) {
int inTime = toMinutes(time.split(":"));
int outTime = toMinutes("23:59".split(":"));
int useTime = outTime - inTime;
if (resultMap.containsKey(carNumber)) {
resultMap.put(carNumber, resultMap.get(carNumber) + useTime);
return;
}
resultMap.put(carNumber, useTime);
}
public int calculate(int[] fees, int parkingTime) {
int defaultTime = fees[0];
int defaultPay = fees[1];
int time = fees[2];
int pay = fees[3];
int useTime = parkingTime;
if (defaultTime >= useTime) {
return defaultPay;
}
useTime -= defaultTime;
int quotient = useTime / time;
if (quotient == 0) {
quotient = 1;
return defaultPay + (pay * quotient);
}
if (((quotient * time) - useTime) != 0) {
quotient += 1;
}
return defaultPay + (pay * quotient);
}
후기
* 난이도 (5점 만점)
5 : 풀 줄 알면 기업 코딩 테스트는 문제없음.
4 : 평균적인 기업 코딩 테스트의 중간 이상.
3 : 평균적인 기업 코딩테스트의 쉬운 문제.
2 : 알고리즘 문제를 연습하고 있다면 풀 수 있는 문제.
1 : 시간이 오래 걸리지 않고, 누구나 풀 수 있는 문제.
시간 계산(시, 분)에 대해 겁먹지 않는다면 차분하게 풀 수 있는 문제입니다. 감사합니다.
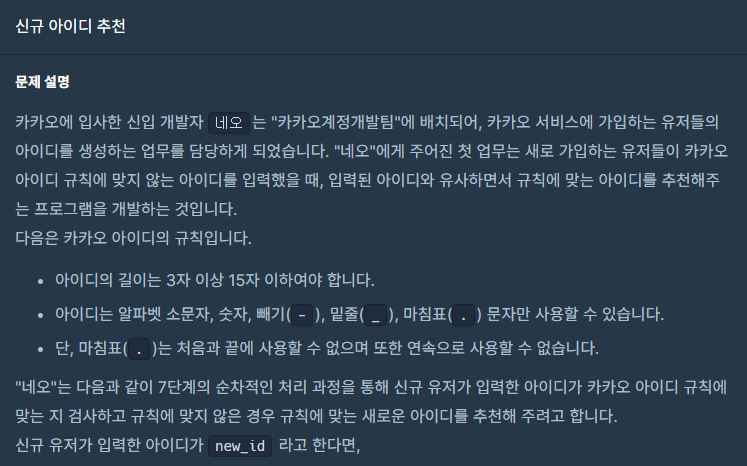
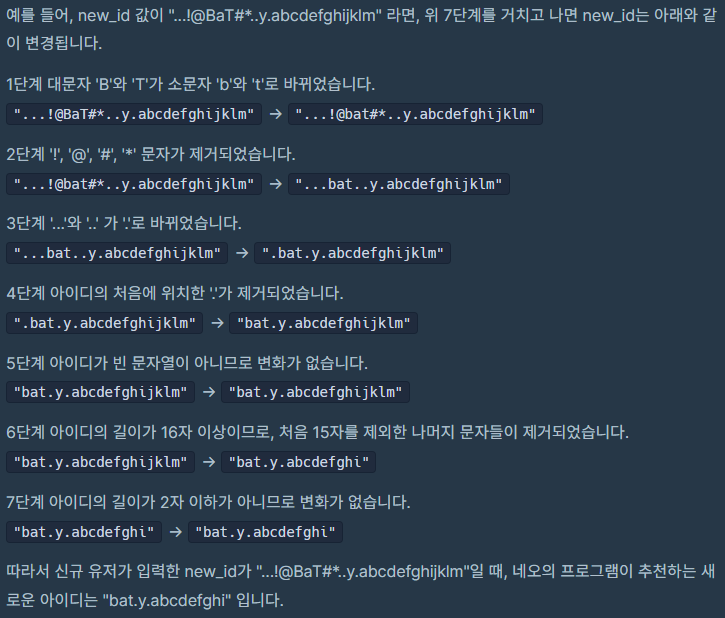
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
풀이
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다. 2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다. 3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다. 4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다. 5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다. 6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다. 만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다. 7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
위의 내용을 하나씩 적용합니다.
1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
return new_id;
}
toLowerCase 함수는 모든 대문자를 대응되는 소문자로 치환해주는 함수입니다. new_id에 toLowerCase 함수를 사용하여 모든 대문자를 대응되는 소문자로 치환해줍니다.
2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
public String emptyWord(String str) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (47 < c && c < 58) {
sb.append(c);
continue;
}
if (96 < c && c < 123) {
sb.append(c);
continue;
}
if ('-' == c || '_' == c || '.' == c) {
sb.append(c);
continue;
}
}
return sb.toString();
}
알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다. 필자는 replace, replaceAll 함수로 특정 문자를 제거하는 것이 아닌 반복문을 사용하여 조건에 해당하는 것만 선별 후 리턴하였습니다. 아스키코드 48 ~ 57은 0~9에 해당하는 값입니다. 아스키코드 97 ~ 122는 알파벳 소문자 a~z에 해당하는 값입니다. 그리고 빼기(-), 밑줄(_), 마침표(.)는 각 char형으로 비교하였습니다.
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
//2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
new_id = emptyWord(new_id);
return new_id;
}
3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
public String closeCheck(String str) {
StringBuffer sb = new StringBuffer();
boolean flag = false;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if ('.' == c) {
if (flag) {
continue;
}
sb.append(c);
flag = true;
continue;
}
sb.append(c);
flag = false;
}
return sb.toString();
}
반복문을 사용했습니다. 마침표(.)가 나왔을 때는 flag = true 로 설정하여 바로 다음 문자가 마침표(.)일 경우 문자를 담지 않고 현재 반복문을 종료 후 다음 반복문을 수행했습니다. 마침표(.) 외의 문자가 나왔을 때는 flag = false로 설정하고 문자를 담은 후 현재 반복문을 종료하고 다음 반복문을 수행했습니다. 결과적으로 마침표(.)가 중복되서 나오는 경우는 최초 1회만 담게 되고 나머지 문자들은 손실 없이 그대로 담기게 됩니다.
ex) aa...bb -> aa.bb
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
//2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
new_id = emptyWord(new_id);
//3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
new_id = closeCheck(new_id);
return new_id;
}
4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
public String startEndCheck(String str) {
if (str.startsWith(".")) {
str = str.substring(1);
}
if (str.endsWith(".")) {
str = str.substring(0, str.length()-1);
}
return str;
}
startWith, endsWith 함수를 사용하여 처음이나 끝에 마침표(.)가 있다면 substring을 이용하여 해당 위치의 문자를 잘라내었습니다.
new_id의 길이가 16자 이상이라면, new_id 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거하는 부분은 삼항연산자로 처리하였습니다. 그리고 만약 제거 후 마침표(.)가 new_id의 끝에 위치했을 때 제거하는 기능은 4단계에서 만들어 놓은 startEndCheck(); 함수를 사용하였습니다. 마침표를 제거한다 라는 역할과 책임을 분리하여 기능을 만들었기 때문에 재사용이 가능했습니다.
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
//2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
new_id = emptyWord(new_id);
//3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
new_id = closeCheck(new_id);
//4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
new_id = startEndCheck(new_id);
//5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
new_id = ("".equals(new_id)) ? "a" : new_id;
//6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
new_id = (new_id.length() >= 16) ? new_id.substring(0, 15) : new_id;
//만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
new_id = startEndCheck(new_id);
return new_id;
}
7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
new_id 길이가 3이 될 때까지가 조건이니 길이 3이상인 문자는 바로 리턴했습니다. 길이 3이상이 아닌 문자의 경우 마지막 글자를 더한 후 다시 길이가 3이상인 문자인지 체크하였고 3이 아니면 마지막 글자를 다시 더한 후 리턴했습니다.
ex) 1. 길이가 3 이상인 경우 바로 리턴.
2. 길이가 2인 경우 "ab" -> 마지막 글자 더하기 -> "abb" -> 길이가 3이상 -> 리턴
3. 길이가 1인 경우 "a" -> 마지막 글자 더하기 -> "aa" -> 마지막 글자 더하기 -> "aaa" -> 길이가 3이상 -> 리턴
4. 길이가 0인 경우 없음 (해당 단계는 7단계입니다. 빈 문자열의 경우 5단계에서 "a"로 치환해줍니다.)
마지막 글자를 더해야 하는 경우는 길이가 1이나 2의 경우입니다. 반복문을 사용하여 처리해도 되지만 최대 2회까지만 마지막 글자를 더해주면 돼서 복잡하게 반복문을 사용하지 않고 처리하였습니다.
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
//2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
new_id = emptyWord(new_id);
//3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
new_id = closeCheck(new_id);
//4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
new_id = startEndCheck(new_id);
//5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
new_id = ("".equals(new_id)) ? "a" : new_id;
//6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
new_id = (new_id.length() >= 16) ? new_id.substring(0, 15) : new_id;
//만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
new_id = startEndCheck(new_id);
//7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
new_id = treeWordCheck(new_id);
return new_id;
}
전체 코드
public String emptyWord(String str) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (47 < c && c < 58) {
sb.append(c);
continue;
}
if (96 < c && c < 123) {
sb.append(c);
continue;
}
if ('-' == c || '_' == c || '.' == c) {
sb.append(c);
continue;
}
}
return sb.toString();
}
public String closeCheck(String str) {
StringBuffer sb = new StringBuffer();
boolean flag = false;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if ('.' == c) {
if (flag) {
continue;
}
sb.append(c);
flag = true;
continue;
}
sb.append(c);
flag = false;
}
return sb.toString();
}
public String startEndCheck(String str) {
if (str.startsWith(".")) {
str = str.substring(1);
}
if (str.endsWith(".")) {
str = str.substring(0, str.length()-1);
}
return str;
}
public String treeWordCheck(String str) {
if (str.length() > 2) return str;
str = str + str.substring(str.length()-1);
return (str.length() > 2) ? str : str + str.substring(str.length()-1);
}
public String solution(String new_id) {
//1단계 new_id의 모든 대문자를 대응되는 소문자로 치환합니다.
new_id = new_id.toLowerCase();
//2단계 new_id에서 알파벳 소문자, 숫자, 빼기(-), 밑줄(_), 마침표(.)를 제외한 모든 문자를 제거합니다.
new_id = emptyWord(new_id);
//3단계 new_id에서 마침표(.)가 2번 이상 연속된 부분을 하나의 마침표(.)로 치환합니다.
new_id = closeCheck(new_id);
//4단계 new_id에서 마침표(.)가 처음이나 끝에 위치한다면 제거합니다.
new_id = startEndCheck(new_id);
//5단계 new_id가 빈 문자열이라면, new_id에 "a"를 대입합니다.
new_id = ("".equals(new_id)) ? "a" : new_id;
//6단계 new_id의 길이가 16자 이상이면, new_id의 첫 15개의 문자를 제외한 나머지 문자들을 모두 제거합니다.
new_id = (new_id.length() >= 16) ? new_id.substring(0, 15) : new_id;
//만약 제거 후 마침표(.)가 new_id의 끝에 위치한다면 끝에 위치한 마침표(.) 문자를 제거합니다.
new_id = startEndCheck(new_id);
//7단계 new_id의 길이가 2자 이하라면, new_id의 마지막 문자를 new_id의 길이가 3이 될 때까지 반복해서 끝에 붙입니다.
new_id = treeWordCheck(new_id);
return new_id;
}
실행결과
후기
* 난이도 (5점 만점)
5 : 풀 줄 알면 기업 코딩 테스트는 문제없음.
4 : 평균적인 기업 코딩 테스트의 중간 이상.
3 : 평균적인 기업 코딩테스트의 쉬운 문제.
2 : 알고리즘 문제를 연습하고 있다면 풀 수 있는 문제.
1 : 시간이 오래 걸리지 않고, 누구나 풀 수 있는 문제.
정답률 57.50% 에 비해 문제가 어렵지 않았다. 이미 문제에서 1~7단계 설명으로 답을 해설해주었기 때문에 쉽게 풀 수 있었다. 단계별로 하나씩 적용하면 코딩테스트 입문자도 풀 수 있는 문제입니다. 감사합니다.
-양의 정수 n이 주어집니다. -이 숫자를 k진수로 바꿉니다. -변환된 수 안에 아래 조건에 맞는 소수(Prime number)가 몇 개인지 봅니다.
0P0처럼 소수 양쪽에 0이 있는 경우
P0처럼 소수 오른쪽에만 0이 있고 왼쪽에는 아무것도 없는 경우
0P처럼 소수 왼쪽에만 0이 있고 오른쪽에는 아무것도 없는 경우
P처럼 소수 양쪽에 아무것도 없는 경우
단,P는 각 자릿수에 0을 포함하지 않는 소수입니다.
예를 들어, 101은P가 될 수 없습니다.
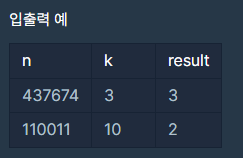
1. 양의 정수 n이 주어집니다.
첫 번째 n: 437674 두 번째 n: 110011
2. 이 숫자를 k진수로 바꿉니다.
첫 번째 k: 3 첫 번째 n을 첫 번째 k진수로 바꿉니다. -> 437674를 3진수로 바꿉니다.
두 번째 k: 10 두 번째 n을 두 번째 k진수로 바꿉니다. -> 110011를 10진수로 바꿉니다.
3. 변환된 수 안에 아래 조건에 맞는 소수(Prime number)가 몇 개인지 봅니다.
0P0처럼 소수 양쪽에 0이 있는 경우
P0처럼 소수 오른쪽에만 0이 있고 왼쪽에는 아무것도 없는 경우
0P처럼 소수 왼쪽에만 0이 있고 오른쪽에는 아무것도 없는 경우
P처럼 소수 양쪽에 아무것도 없는 경우
단,P는 각 자릿수에 0을 포함하지 않는 소수입니다.
예를 들어, 101은P가 될 수 없습니다.
0을 기준으로 숫자를 나눠서 해당 숫자가 소수인지 판별하는 방법입니다.
첫 번째 n인 437674를 3진수로 변환하면 211020101011입니다. 211020101011의 경우는 211020101011 0을 기준으로 211, 2, 1, 1, 11 총 5개의 수가 나옵니다.
첫 번째 211은 소수입니다. 두 번째 2는 소수입니다. 세 번째 1은 소수가 아닙니다. 네 번째 1은 소수가 아닙니다. 다섯 번째 11은 소수입니다. 그러므로 211020101011의 5개 의 숫자 중 3개의 소수가 있습니다.
위의 입출력 예와 같이 437674를 3진수로 변환 후 소수를 구했을 때 답은 3이 나옵니다.
두 번째 n인 110011를 10진수로 변환하면 110011입니다. 110011의 경우는 110011 양 쪽 11과 11이 조건에 맞는 수 입니다 첫 번째11은 소수입니다. 두 번째11은 소수입니다. 그러므로 110011의 양 쪽에 소수가 하나씩 있으므로 총 2개의 소수가 있습니다.
위의 입출력 예와 같이 110011를 10진수로 변환 후 소수를 구했을 때 답은 2가 나옵니다.
문제 풀이 방법은 위와 같은 순서로 진행될 것입니다.
1. 소수 합계를 반환해줄 answer가 있습니다. 2. 양의 정수 n을 k진수로 변환합니다. 3.k진수로 변환된 n의 소수 합계를 구합니다. 4. 소수 합계를 반환합니다.
import java.util.StringTokenizer;
class Solution {
// 정수 n이 소수인지 판별하는 함수
public boolean isPrime(Long n) {
if (n < 2) return false;
if (n == 2) return true;
for (int i = 2; i <= Math.sqrt(n); i++) if(n % i == 0) return false;
return true;
}
// 정수 n을 k진수로 변환하는 함수
public Long toEverynary (int n, int k) {
return Long.parseLong(Integer.toString(n,k));
}
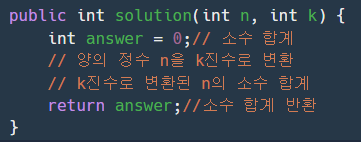
public int solution(int n, int k) {
int answer = 0;// 소수 합계
// toEverynary 함수는 의 정수 n을 k진수로 변환합니다.
// StringTokenizer를 "0"으로 구분하여 생성하면 0 을 제외한 값으로만 값이 생성됩니다.
// 만약 split("0")으로 처리한다면 0이 연속으로 나오는 0000 의 경우 빈 공백의 배열이 생성될 것입니다.
StringTokenizer token = new StringTokenizer(Long.toString(toEverynary(n, k)), "0");
// token안에 담긴 수 만큼 반복문을 실행하여 해당 수가 소수인지 판별 후 소수인 경우만 소수 합계에 더해줍니다.
while (token.countTokens() > 0) {
if (isPrime(Long.parseLong(token.nextToken()))) answer++;
}
return answer;// 소수 합계를 반환합니다.
}
}
주석 없는 버전
import java.util.StringTokenizer;
class Solution {
public boolean isPrime(Long n) {
if (n < 2) return false;
if (n == 2) return true;
for (int i = 2; i <= Math.sqrt(n); i++) if (n % i == 0) return false;
return true;
}
public Long toEverynary (int n, int k) {
return Long.parseLong(Integer.toString(n,k));
}
public int solution(int n, int k) {
int answer = 0;
StringTokenizer token = new StringTokenizer(Long.toString(toEverynary(n, k)), "0");
while (token.countTokens() > 0) {
if (isPrime(Long.parseLong(token.nextToken()))) answer++;
}
return answer;
}
}
후기
* 난이도 (5점 만점)
5 : 풀 줄 알면 기업 코딩 테스트는 문제없음.
4 : 평균적인 기업 코딩 테스트의 중간 이상.
3 : 평균적인 기업 코딩테스트의 쉬운 문제.
2 : 알고리즘 문제를 연습하고 있다면 풀 수 있는 문제.
1 : 시간이 오래 걸리지 않고, 누구나 풀 수 있는 문제.
이 문제는 "k진수"라는 단어와 "소수 판별"이라는 단어에 겁먹지 않는다면 충분히 풀 수 있는 문제입니다. 문제를 풀 때 한 번에 모든 것을 해결하려 하지 말고 단계 별로 풀이를 정해서 차근차근 풀어나간다면 어렵지 않은 문제입니다.
클로저는 이미 생명 주기상 끝난 외부 함수의 변수를 참조하는 함수입니다. 클로저는 여러 함수형 프로그래밍 언어에서 등장하는 보편적인 특성입니다. 자바스크립트 고유의 개념이 아닙니다.
구현
var outer = function () {
var a = 1;
var inner = function () {
return ++a;
}
return inner;
}
var outer2 = outer();
console.log(outer2());
console.log(outer2());
위의 코드 결과를 보면 2와 3이 출력됩니다. 작성순서는 이렇습니다. -outer 함수 구현 -outer2 선언 -console.log로 outer2 출력 (첫 번째) -console.log로 outer2 출력 (두 번째)
하나씩 풀이해보면 처음 outer 함수를 보면 inner 함수 내부에서 외부변수인 a를 사용합니다. 그런데 outer 함수 결과는 inner 함수를 리턴하고 있습니다. outer 함수의 실행 컨텍스트가 종료된 시점에는 a 변수를 참조하는 대상이 없어집니다. 하지만 참조 카운트가 0이 아니어서 가지비 컬렉터 대상이 아닙니다. 생명주기가 끝난 것으로 보이지만 외부에서 사용할 수 있습니다. 이렇게 이미 생명 주기상 끝난 외부 함수의 변수를 참조하는 것을 클로저라고 합니다.
로그 추가
위의 소스코드 중간마다 로그를 찍어보겠습니다.
console.log('========== 시작 ==========');
var outer = function () {
var a = 1;
console.log('a: ',a);
var inner = function () {
return ++a;
}
return inner;
}
console.log('A');
var outer2 = outer();
console.log('B');
console.log('a: ', outer2());
console.log('C');
console.log('a: ', outer2());
console.log('========== 종료 ==========');
로그A 밑에 outer2를 선언할 때 처음 outer 함수를 읽어옵니다. a를 1로 선언했으니 로그에는 a의 값은 1입니다.
로그B 밑에 outer2를 콘솔로 출력할 때 outer 함수의 리턴 값인 inner를 실행시킵니다. inner 함수가 실행되어서 ++a가 결과인 2가 결과로 나옵니다.
로그C 밑에 outer2를 콘솔로 출력할 때 outer 함수의 리턴 값인 inner를 실행시킵니다. inner 함수가 실행되어서 ++a가 결과인 3가 결과로 나옵니다.
클로저는 자바스크립트에만 사용되는 개념인가?
클로저는 자바스크립트 고유의 개념이 아닙니다. 함수형 프로그래밍 개념입니다.
후기
클로저를 공부하기 전에는 단순히 프론트앤드, 자바스크립트의 개념이라고 생각했는데 함수형 프로그래밍에 사용되는 개념이었습니다. 자바와 스프링에 대해 공부하다가 자바스크립트를 사용할 일이 생겨서 공부 중인데 결과적으로 자바와 스프링에도 도움이 되고있습니다.
이터레이터 패턴은 컬렉션 구현 방법을 노출시키지 않으면서도 그 집합체 안에 들어있는 모든 항목에 접근할 수 있게 해주는 방법을 제공해 줍니다.
Iteratoer Pattern 어떻게 구현할까요?
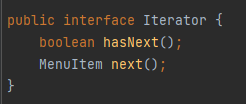
이터레이터 패턴은 Iterator라는 인터페이스에 의존합니다. 이터레이터 패턴은 이용하면 내부적인 구현 방법을 외부로 노출시키지 않으면서도 집합체에 있는 모든 항목에 일일이 접근할 수 있습니다. 또한 각 항목에 일일이 접근할 수 있게 해주는 기능을 집합체가 아닌 반복자 객체에서 책임지게 된다는 것도 장점으로 작용합니다. 그러면 집합체 인터페이스 및 구현이 간단해지고, 각자 중요한 일만 처리하면 됩니다.
hasNext와 next라는 함수만 노출시킵니다. 이 함수를 사용하는 사용자는 hasNext가 boolean으로 되어있으니 다음 데이터가 있는지 여부를 반환하는 함수라고 예측 가능하고, Next는 MenuItem이라는 객체를 반환하니 객체에 담겨있는 다음 데이터를 보여주는구나라고 예측할 수 있습니다. 하지만 내부적인 구현 방법은 모릅니다. 이렇게 구현 방법을 외부로 노출시키지 않고 기능을 제공할 수 있습니다.
package cg.park.designpattern.iterator;
public class WashMenuIterator implements Iterator {
MenuItem[] items;
int position = 0;
public WashMenuIterator(MenuItem[] items) {this.items = items;}
public MenuItem next() {return items[position++];}
public boolean hasNext() {return items.length > position;}
}
Menu
package cg.park.designpattern.iterator;
public interface Menu {
public Iterator createIterator();
}
WashMenu
package cg.park.designpattern.iterator;
public class WashMenu implements Menu {
static final int MAX_ITEMS = 6;
int numberOfItems = 0;
MenuItem[] menuItems;
public WashMenu() {
menuItems = new MenuItem[MAX_ITEMS];
addItem("카 샴푸");
addItem("세차용 스폰지");
addItem("휠 브러시 사용");
addItem("물통에 스폰지 세척");
addItem("고압수 뿌리기");
addItem("타월을 이용하여 물기 제거");
}
public void addItem(String description) {
MenuItem washItem = new MenuItem(description);
if (numberOfItems >= MAX_ITEMS) {
System.out.println("최대 개수를 초과했습니다.");
return;
}
menuItems[numberOfItems] = washItem;
numberOfItems++;
}
public MenuItem[] getMenuItems() {
return menuItems;
}
public Iterator createIterator() {
return new WashMenuIterator(menuItems);
}
}
MenuItem
package cg.park.designpattern.iterator;
public class MenuItem {
String description;
public MenuItem(String description) {
this.description = description;
}
public String getDescription() {
return description;
}
public String toString() { return description; }
}
Cleaner
package cg.park.designpattern.iterator;
public class Cleaner {
Menu washMenu;
public Cleaner(Menu washMenu) {
this.washMenu = washMenu;
}
public void cleaning() {
System.out.println("==========청소 시작==========");
printCleaning(washMenu.createIterator());
System.out.println("==========청소 끝==========");
}
private void printCleaning(Iterator iterator) {
while (iterator.hasNext()) {
MenuItem menuItem = iterator.next();
System.out.println(menuItem.description);
}
}
}
IteratorTest
package cg.park.designpattern.iterator;
public class IteratorTest {
public static void main(String[] args) {
Cleaner cleaner = new Cleaner(new WashMenu());
cleaner.cleaning();
}
}
후기
내부적인 구현 방법을 외부로 노출시키지 않으면서도 집합체에 있는 모든 항목에 일일이 접근할 수 있는 방법은 유용한 기술입니다.
객체 지향 프로그래밍(Object-Oriented Programming)은 컴퓨터 프로그래밍의 패러다임 중 하나입니다. 객체 지향 프로그래밍은 컴퓨터 프로그램을 명령어의 목록으로 보는 시각에서 벗어나 여러 개의 독립된 단위, 즉 "객체"들의 모임으로 파악하고자 하는 것입니다. 각각의 객체는 메시지를 주고받고, 데이터를 처리할 수 있습니다. 객체 지향 프로그래밍은 프로그램을 유연하고 변경이 쉽게 만들기 때문에 대규모 소프트웨어 개발에 많이 사용됩니다. 또한 프로그래밍을 더 배우기 쉽게 하고 소프트웨어 개발과 보수를 간편하게 하며, 보다 직관적인 코드 분석을 가능하게 하는 장점이 있습니다. 그러나 지나친 프로그램의 객체화 경향은 실제 세계의 모습을 그대로 반영하지 못한다는 비판을 받기도 합니다.
객체지향 언어의 역사
초창기에는 주로 과학실험이나 미사일 발사 실험과 같은 모의실험을 목적으로 사용되었습니다. 모의실험을 위해 실제 세계와 유사한 가상 세계를 컴퓨터 속에 구현하고자 노력하였으며 이러한 노력을 바탕으로 객체지향 이론을 탄생시켰습니다.
객체지향이론 개념
객체지향 이론의 기본 개념은 실제 세계의 사물(객체)로 이루어져 있으며, 발생하는 모든 사건들은 사물 간의 상호작용이다.라는 것입니다. 객체지향 이론은 상속, 캡슐화, 추상화 개념을 중심으로 점차 구체적으로 발전되었습니다. 최초의 객체지향 언어는 1960년대 중반에 객체지향이론을 프로그래밍언어에 적용한 시뮬라(Simula)라는 언어입니다. 자바가 1995년에 발표되고 1990년대 말에 인터넷의 발전과 함께 크게 유행하면서 객체지향언어는 프로그래밍 언어의 주류로 자리 잡았습니다.
객체지향 언어의 주요 특징
코드의 재사용성이 높다. 새로운 코드를 작성할 때 기존의 코드를 이용하여 작성할 수 있습니다.
코드 관리가 용이하다. 코드 간의 관계를 이용해서 코드를 변경할 수 있습니다.
신뢰성이 높은 프로그래밍을 가능하게 한다. 제어자와 메서드를 이용해서 데이터를 보호하고 올바른 값을 유지하도록 하며, 코드의 중복을 제거하여 코드의 불일치로 인한 오작동을 방지할 수 있습니다.
객체 지향 프로그래밍 5 원칙
단일 책임 원칙 (Single responsibility principle) 한 클래스는 하나의 책임만 가져야 합니다.
개방-폐쇄 원칙 (Open/closed principle) 소프트웨어 요소는 확장에는 열려 있으나 변경에는 닫혀 있어야 합니다.
리스 코프 치환 원칙 (Liskov substitution principle) 프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 합니다.
인터페이스 분리 원칙 (Interface segregation principle) 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫습니다.
의존관계 역전 원칙 (Dependency inversion principle) 프로그래머는 “추상화에 의존해야지, 구체화에 의존하면 안 된다.” 의존성 주입은 이 원칙을 따르는 방법 중 하나입니다.
자바는 썬 마이크로시스템즈(Sun Microsystems)에서 개발하여 1996년 1월에 공식적으로 발표한 객체지향 프로그래밍 언어입니다. 자바의 가장 중요한 특징은 운영체제에 독립적이라는 것입니다. 자바로 작성된 프로그램은 운영체제의 종류에 관계없이 실행이 가능하기 때문에, 운영체제에 따라 프로그램을 변경하지 않고, 실행이 가능합니다.
자바의 역사
자바의 역사는 1991년에 썬의 엔지니어들에 의해 고안된 오크(Oak)라는 언어에서부터 시작되었습니다. 처음에는 C++을 확장해서 사용하려 했지만 C++로는 목적을 이루기에 부족하다는 것을 알게 되었습니다. 그래서 C++의 장점을 도입하고 단점을 보완한 새로운 언어를 개발하기 시작했습니다. 처음에는 가전제품이나 PDA와 같은 소형기기에 사용될 모적이었으나 여러 종류의 운영체제를 사용하는 컴퓨터와 인터넷이 등장하자 운영체제에 독립적인 Oak가 이에 적합하다고 판단하였습니다. Oak를 인터넷에 적합하도록 그 개발 방향을 바꾸면서 이름을 자바로 변경하였고, 자바로 개발한 웹브라우저인 핫 자바를 발표하고 그다음 해인 1996년 1월에 자바의 정식 버전을 발표했습니다.
자바언어의 특징
운영체제에 독립적 자바로 만든 프로그래밍은 운영체제와 하드웨어에 관계없이 실행 가능하며 이것을 한 번 작성하면, 어디서나 실행된다.(Write once, run anywhere)라고 표현하기도 합니다.
객체지향 언어 자바는 객체지향 프로그래밍 언어 중 하나로 객체지향 개념의 특징인 상속, 캡슐화, 다형성이 잘 적용된 수수한 객체지향 언어입니다.
자동 메모리 관리(Garbage Collection) 자바로 작성된 프로그램이 실행되면, 가비지 컬렉터(Garbage Collector)가 자동적으로 메모리관리를 해줍니다. 가비지컬렉터(Garbage Collector)가 없다면 개발자가 사용하지 않는 메모리를 체크하고 반환하는 일을 수동적으로 처리해야 할 것입니다. 개발자가 개발에 집중할 수 있도록 도와줍니다.
네트워크와 분산처리를 지원 다양한 네트워크 프로그래밍 라이브러리(Java API)를 통해 네트워크 관련 프로그램을 개발할 수입니다.
멀티스레드(Multi-thread) 자바에서 개발되는 멀티스레드 프로그램은 시스템과는 관계없이 구현 가능하며, 관련된 라이브러리(Java API)가 제공되므로 구현이 어렵지 않습니다. 여러 스레드에 대한 스케줄링을 자바 인터프리터가 담당하고 있습니다.
동적 로딩(Dynamic Loading) 자바로 만들어진 애플리케이션은 여러 개의 클래스로 구성되어 있습니다. 자바는 동적으로 로딩을 지원하기 때문에 실행 시에 모든 클래스를 로딩하지 않고, 필요한 시점에 클래스를 로딩하여 사용할 수 있습니다.
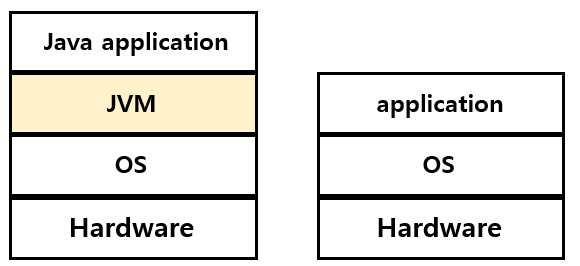
JVM (Java Virtual Machine)
자바를 실행하기 위한 가상 기계인 JVM (Java Virtual Machine)은 자바의 특징이자 장점이다. 일반 어플리케이션 코드는 OS만 거치고 하드웨어로 전달되지만, 자바 어플리케이션은 JVM을 거쳐서 전달됩니다. 일반 어플리케이션은 OS와 바로 맞붙어 있기 때문에 OS 종속적입니다. 그래서 다른 OS에서 실행시키기 위해서는 애플리케이션을 그 OS에 맞게 변경해야 하는 번거로움이 있습니다. 반면에 자바 애플리케이션은 JVM 하고 상호작용하기 때문에 OS와 하드웨어에 독립적입니다. 다른 OS에서도 프로그램의 변경 없이 실행이 가능합니다.
후기
자바를 사용하는 개발자는 압도적으로 많습니다. 자바를 왜 사용하는지 생각해볼 필요가 있습니다.